
 2026年01月16日
2026年01月16日人工智能技术高速发展推动全球算力需求指数级攀升。从生成式AI爆发,到自动驾驶、智慧医疗等领域应用突破,大模型参数量已从亿级迈向万亿级,在此背景下算力利用率偏低成为核心制约。据英伟达、斯坦福及微软研究,大模型训练的算力利用率仅44%-55%,大量硬件资源处于闲置状态。
这一问题的核心瓶颈在于传统互联架构难以承载并行训练的海量通信需求,带宽、延迟等方面的短板严重制约万卡级集群效率提升。光直连超节点技术凭借高带宽、低延迟、强抗扰等特性,有望成为破解算力浪费、构建高效 AI集群的关键。
| 深耕光互联算力核心技术
光子算数是国内领先的光互联算力集群解决方案提供商,秉持“用光改变计算”的理念,以光通信、光电集成、NPO/CPO等技术为核心,深度融合国产GPU芯片,为用户提供创新、高效、可靠的光互联算力产品及解决方案。
作为光互联算力领域的前沿开拓者与产业实践者,公司坚持以创新驱动发展,依托深厚的技术积累,构建了安全可控的核心技术体系。凭借扎实的工程化落地能力,光子算数产品为人工智能、仿真等关键领域提供高效、稳定、绿色的算力支撑,持续推动千行百业的数字化升级。
| 光直连超节点定义光互联新范式
光子算数推出的光直连超节点系统,采用线性直驱光互联技术,将光互联芯片与国产GPU芯片板卡级集成,实现了GPU加速卡间的直接高速互联,突破了传统电互联在传输距离、信号质量和扩展性上的限制,实现AI计算效率质的提升。
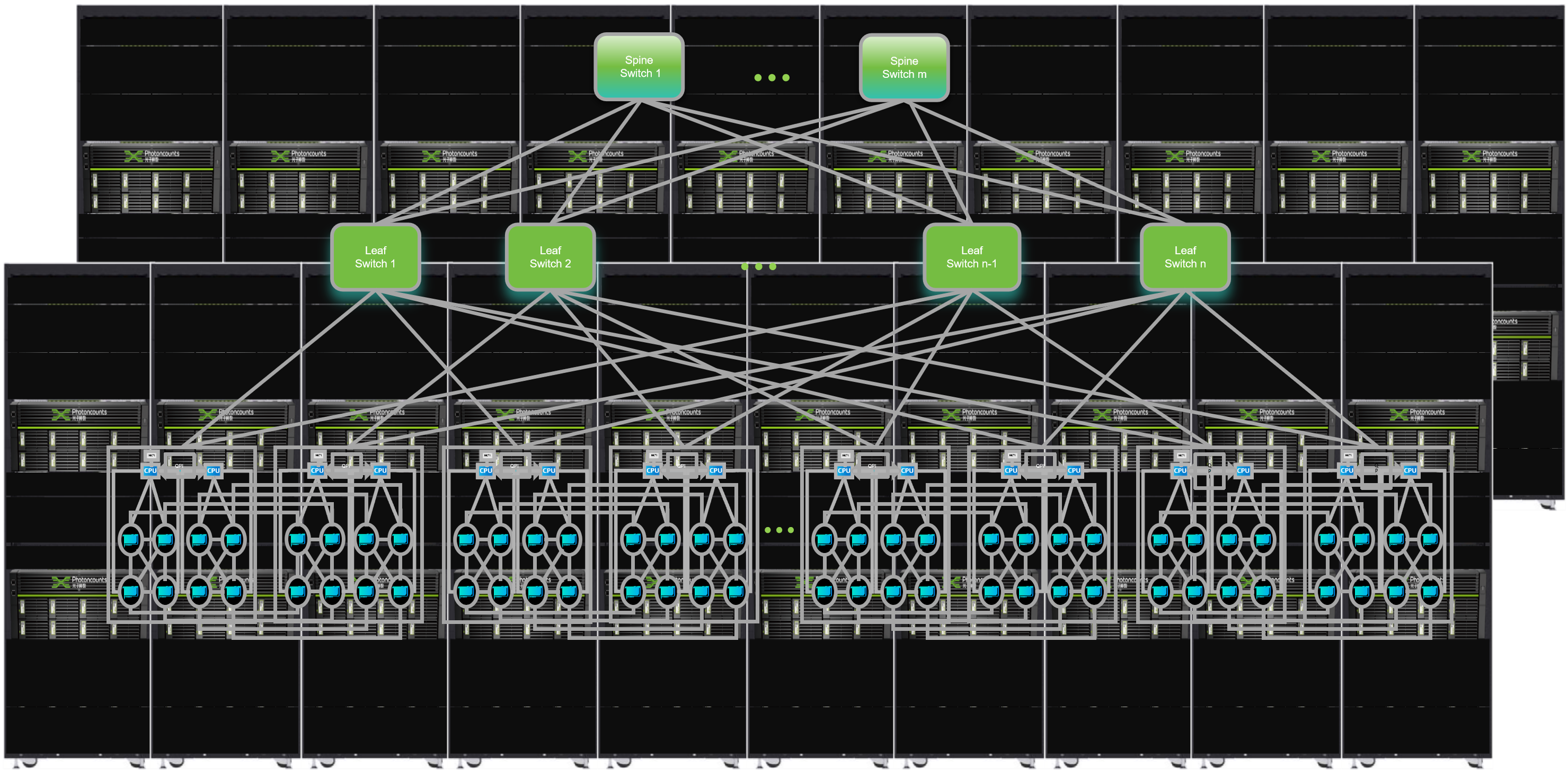
▲光直连超节点系统示意图
其核心技术在于“硬、网、软协同”的系统级创新,大幅提升计算效率。硬件上,依托在光互联和光电集成等方面的深厚积累,与国产GPU芯片深度协同设计,打造光电混合的光直连GPU加速卡,实现光电协同。同时,基于光直连GPU加速卡,构建Scale Up域光直连网络架构,实现GPU加速卡间的高效互联通信,有效匹配业务、算法等方面的需求。软件栈方面,深度优化匹配光电混合硬件与网络架构的集合通信库等软件栈,提升整体通信效率。
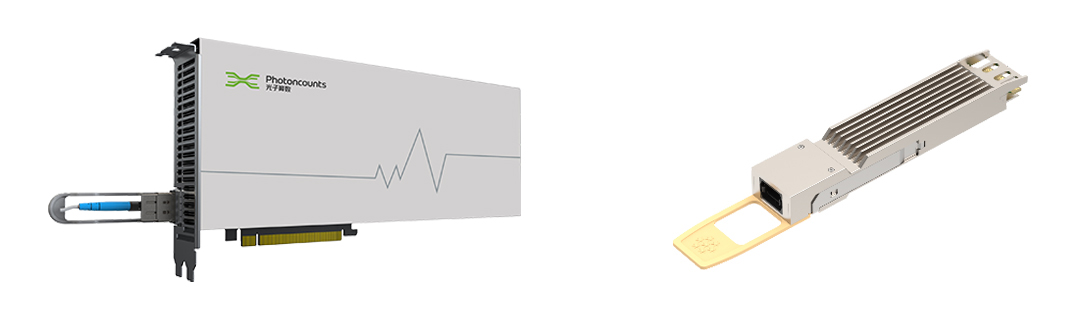
▲光直连AI加速卡及配套光互联模块
光直连超节点系统,是全新一代高效率的AI算力底座,在兼容性、算力、互联带宽、部署方面具有显著优势。
• 兼容性优秀:采用标准协议,支持国内主流GPU芯片,实现GPU芯片直接驱动光信号,用于构建大规模GPU芯片间高效通信网络。
• 大算力:单套产品可提供高达上百P甚至几百P算力,满足千亿参数大模型训练/推理需求。
• 高带宽:对外提供2Tb/s的超高规格光互联带宽。
• 易部署:兼容标准服务器和机柜,可实现高效部署,降低改造成本。
值得关注的是,光子算数光直连超节点系统已于2025年正式实现量产交付,这标志着光直连超节点技术迈入规模化商业落地的全新阶段,量产交付的背后是公司对核心技术的持续打磨与工程化能力的全面验证。
| 扎根关键领域,服务重大需求
光子算数深度联动服务器、光模块加工、板卡加工以及电芯片等上下游伙伴,同时与高校、科研机构开展长期产学研合作,在推动光学技术产业协同的同时,加速实现技术成果转化。凭借在批量交付、升级迭代、质量管控等方面的显著优势,目前,公司已在交通、环保、工业制造等关键场景完成实践部署,正式跻身算力基础设施建设服务商序列,为重大需求提供高效、稳定、绿色的AI算力支撑。
未来,光子算数将锚定 “核心技术持续演进、产品体系自主可控、产业生态开放共建” 三大方向,持续拓展光直连超节点系统市场,推动产业落地与价值释放,为人工智能产业迈向高质量发展新阶段注入强劲动能。

