
 2026年04月07日
2026年04月07日随着AI模型的规模爆发,构建万卡级算力集群成为常态,传统电交换需要反复进行“光-电-光”转换,存在延迟高、功耗高、带宽密度受限且每代速率升级都需更换整机等问题。在刚刚落幕的全球光通信顶级盛会OFC 2026上,OCS(光交换机)成为贯穿AI算力与光通信两大领域的绝对热点。OCS因其支持更大规模无阻塞互联与动态拓扑调整,可显著提升集群通信效率、降低整体能耗与运维成本,被视为下一代智算中心网络革新的关键。
| OCS:AI算力集群的全场景网络密钥
根据英伟达在OFC 2026大会上的阐述,OCS在AI算力集群的价值贯穿三大核心场景:
在Scale-up场景中:OCS能构建灵活、高效的大规模光互联GPU资源池,实现算力按需分配,规避设备运维、升级时的业务中断,极大提升系统可用性。
在Scale-out场景中:OCS可插入电交换层之间,利用光互联优势提升网络弹性与故障恢复能力,或替代Spine层电交换机,构建更低功耗、更低延迟的扁平化网络。
在Scale-across场景中:OCS则适用于园区楼宇或远程算力集群之间的光互联,提供高带宽、灵活的长距离组网能力。
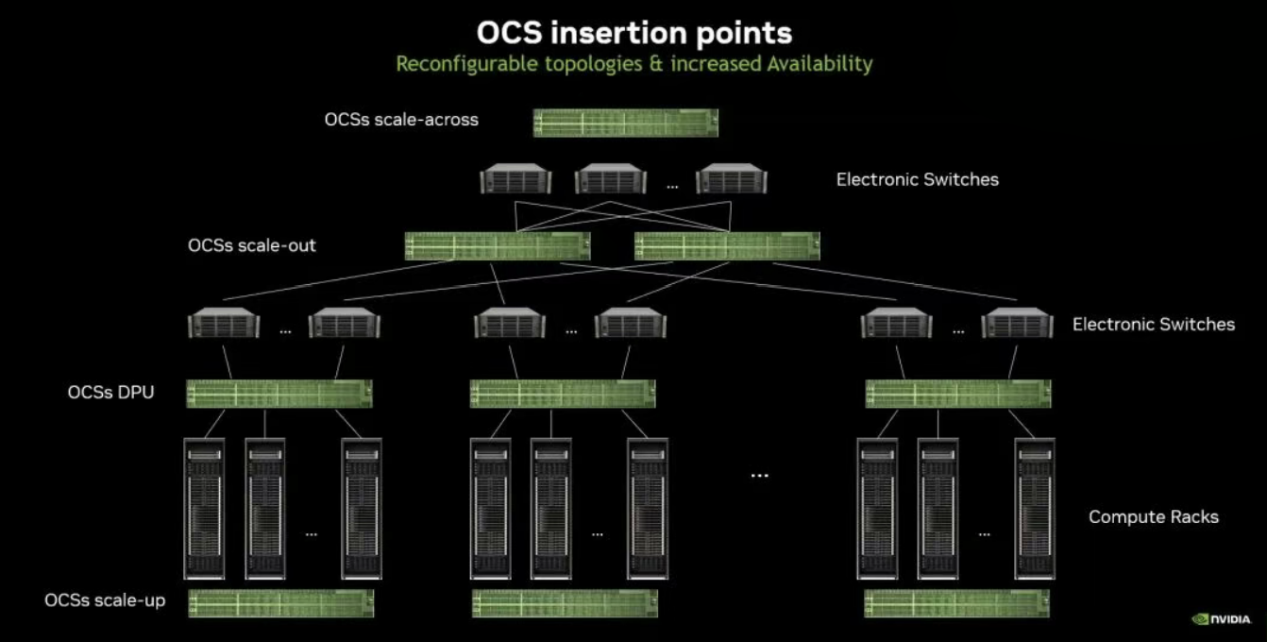
▲OCS在AI算力集群的核心介入点,来源:英伟达
行业数据也印证了这一趋势。Lumentum透露,已获得数十亿美元的多年期OCS协议,并预测2025至2028财年,OCS出货量的年复合增长率将超过150%。Cignal AI预测,到2029年OCS市场规模将突破30亿美元。
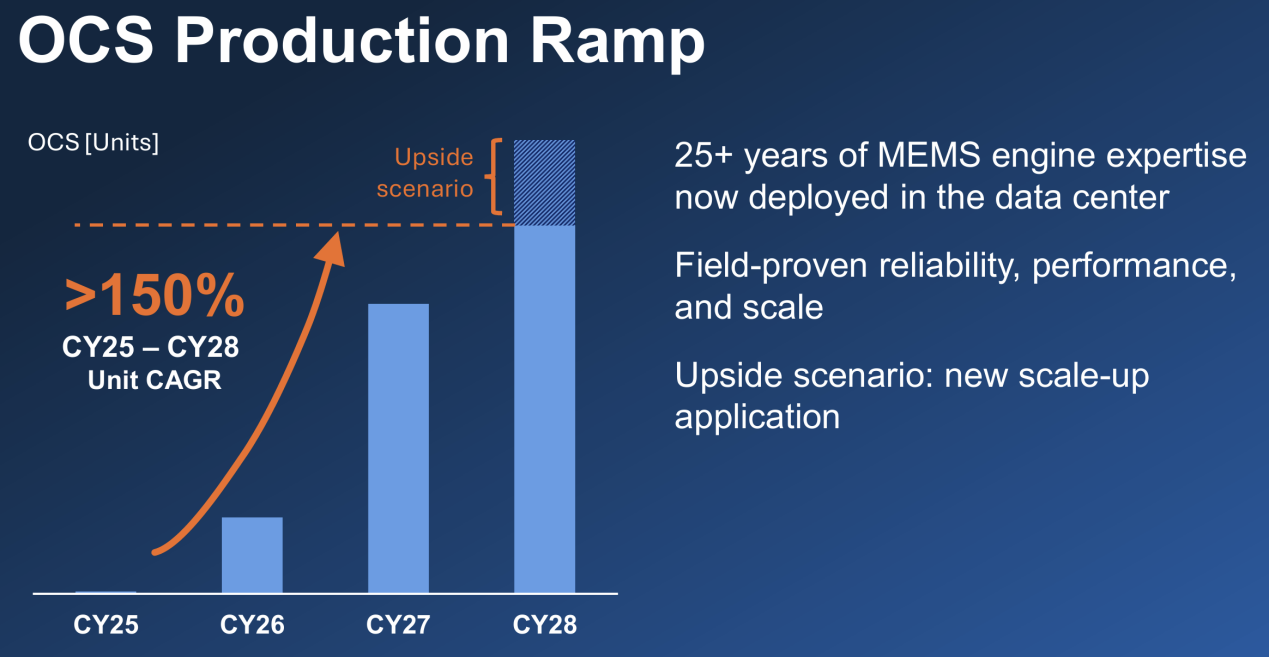
▲Lumentum OCS出货量将迎来快速增长,来源:Lumentum
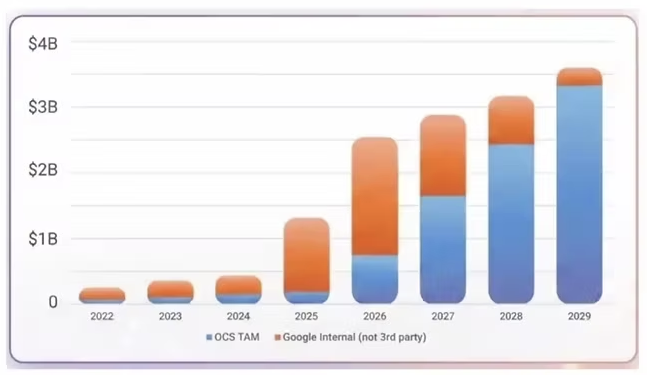
▲2029年OCS市场规模将突破30亿美元,来源:nEye
| 理想与现实:OCS规模商用之路的挑战
目前,基于MEMS技术的OCS拥有光学性能优、端口扩展性强、可靠性高的特点,是商用化的主流选择;而随着技术的不断演进,拓扑切换速度更高的硅光2D OCS有望成为下一代OCS的发展方向。
OFC 2026上,Lumentum与Marvell联合展出了机架级OCS整机系统,该系统基于Marvell的光互联解决方案与Lumentum基于MEMS技术推出的OCS R300,实现了动态高带宽的光通路,有效降低时延与功耗,并提升整体网络效率。

▲Lumentum R300 OCS,来源:Converge Network Digest
iPronics的OCS采用硅光为核心的2D OCS技术实现,拥有256端口/1U的超高密度,功耗低至0.78W/端口,插损预计2027年降至4-5dB;nEye的2D OCS方案通过SiPh+MEMS+CMOS集成,实现亚微秒级切换、<5ns时延和<5W功耗,相比传统3D OCS在性能上实现数量级提升。

▲3D OCS VS 2D OCS,来源:nEye
国内厂商快速突破,国产OCS产业链在加速成型:
新易盛采用自主研发MEMS微镜阵列,推出NX200和NX300系列OCS,分别支持140端口和320端口,可灵活适配不同规模AI集群的组网需求。
光迅科技利用MEMS mirror阵列芯片和光纤阵列单元FAU两大核心组件的自研能力,推出了320×320 OCS产品,该产品插损典型值达1.5dB,可支撑复杂叶脊架构互连。

▲新易盛OCS产品图示,来源:新易盛
尽管前景广阔,但目前只有Google在Apollo项目中,针对自身业务的精准把控实现了OCS的落地。这意味着在整个行业中,OCS从实验室原型到稳定可靠的算力集群产品,其技术仍需经历一个持续的优化和成熟过程。对于亟需构建高效的算力集群的客户而言,网络的绝对稳定、可靠是业务的基石。
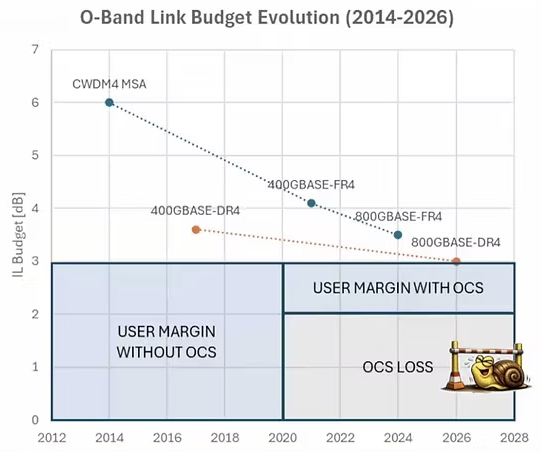
▲OCS插入损耗较高,来源:Ciena
| 光子算数以NPO光电融合筑基当下算力需求,瞄准全光未来
面对“未来已来,尚未普及”的窗口期,光子算数立足客户业务的现实需求,选择了一条融合演进的路径:新一代PhotonFlare光直连GPU超节点系统将采用NPO光电融合交换机技术,不仅降低了网络系统的功耗和延迟,算力集群的效率相比第一代大幅提升,还有效解决了大规模集群对高性能、高可靠网络的核心需求。
同时,光子算数积极携手国内领先的OCS技术厂商、光学元件供应商及芯片合作伙伴展开深度合作。通过联合研发、测试验证与生态共建,加速OCS关键技术的成熟,探索OCS与PhotonFlare光直连GPU超节点系统的最优集成方案,为未来平滑升级至全光交换网络做好准备,共同定义面向超大规模AI集群的下一代网络架构标准。
网络是算力集群的“神经系统”。光子算数对先进交换技术的持续投入,无论是当前推动NPO光电融合交换机的规模化应用,还是对未来全光OCS的积极布局,都将确保我们的解决方案始终站在技术演进的最前沿,为用户提供创新、高效、可靠的光互联算力产品及解决方案。

