
 2026年02月10日
2026年02月10日超节点作为新一代AI基础设施,彻底颠覆了传统智算集群“分散作战”的低效模式,本质上是通过高速的互联网络将算力资源从“分散利用”升级为“集群聚合”,宛如为AI算力打造了一张“超级高铁网”——不仅具备高速、高效、无缝连接的特性,更成为突破算力瓶颈、释放AI核心潜力的关键,而光互联技术则像是为整个超节点互联网络插上了“翅膀”,进一步提升了整体效率。
| 超节点网络架构搭建的两大核心挑战
超节点网络面临的首要问题是"算力空转"。随着芯片算力指数级增长,内存带宽和网络带宽却严重滞后,导致数据供给跟不上计算速度。解决方案需从三个层面协同发力:芯片层面采用HBM3e、LPDDR5X等高带宽内存;网络层面引入光互联等高速互联方式;系统层面优化数据流调度策略。
第二个挑战来自MoE模型的All-to-All通信难题。混合专家模型参数庞大且采用动态路由,训练过程中频繁触发全对全通信,对网络延迟极度敏感。光互联网络能够从通信方式、网络拓扑和软件调度三方面进行深度优化,满足通信带宽和延迟的要求。
| 网络拓扑结构的研究
超节点网络的发展历程体现了拓扑结构逐步适应算力规模扩张的过程。
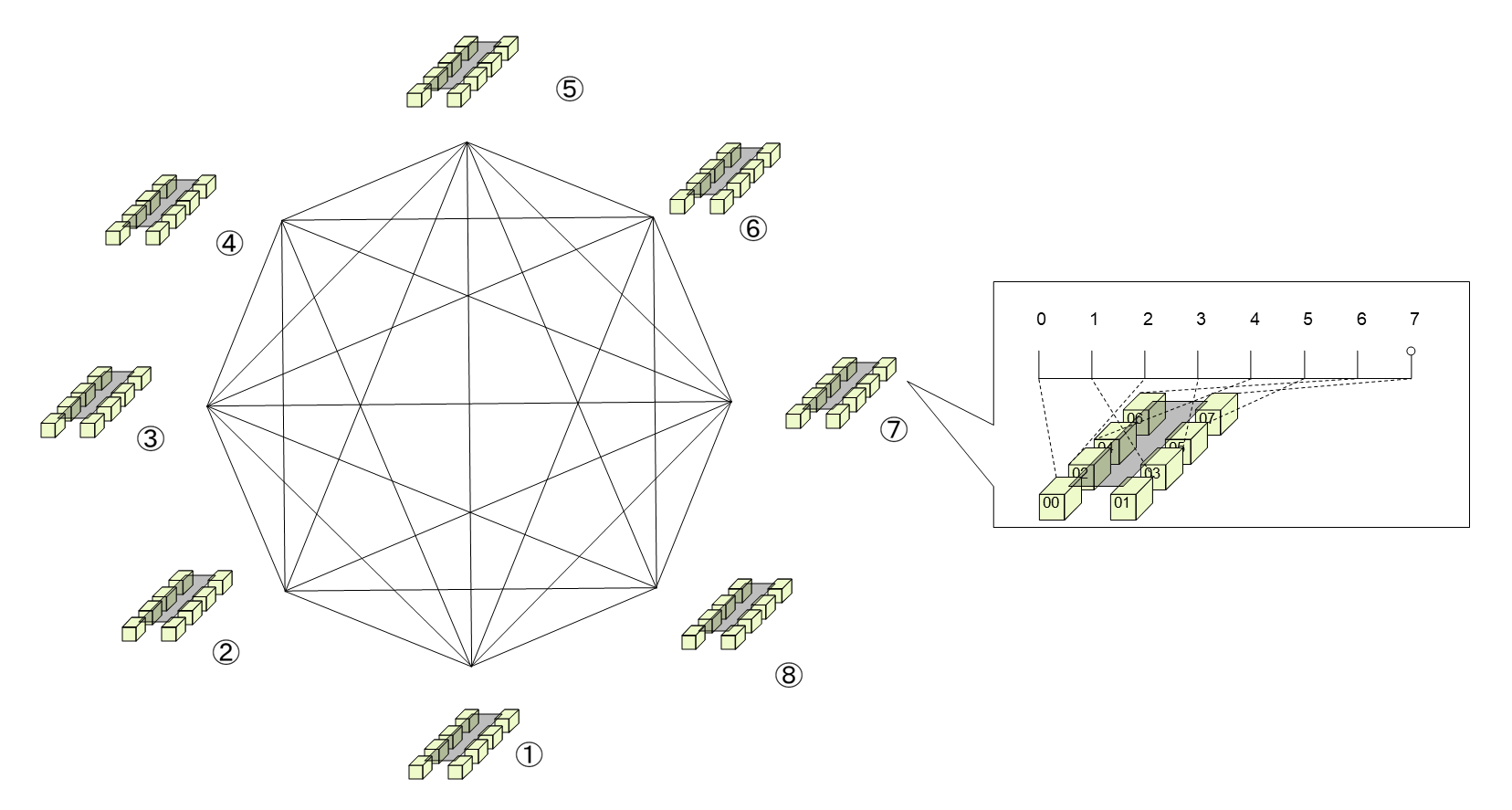
早期阶段: 全互联拓扑。最初的Scale-up架构演进表现为单机GPU直连扩展为双机直连模组,采用全互连(Full Mesh)拓扑。这种方式依赖硬件层面的互联能力,但受限于物理连接数量,难以大规模扩展。
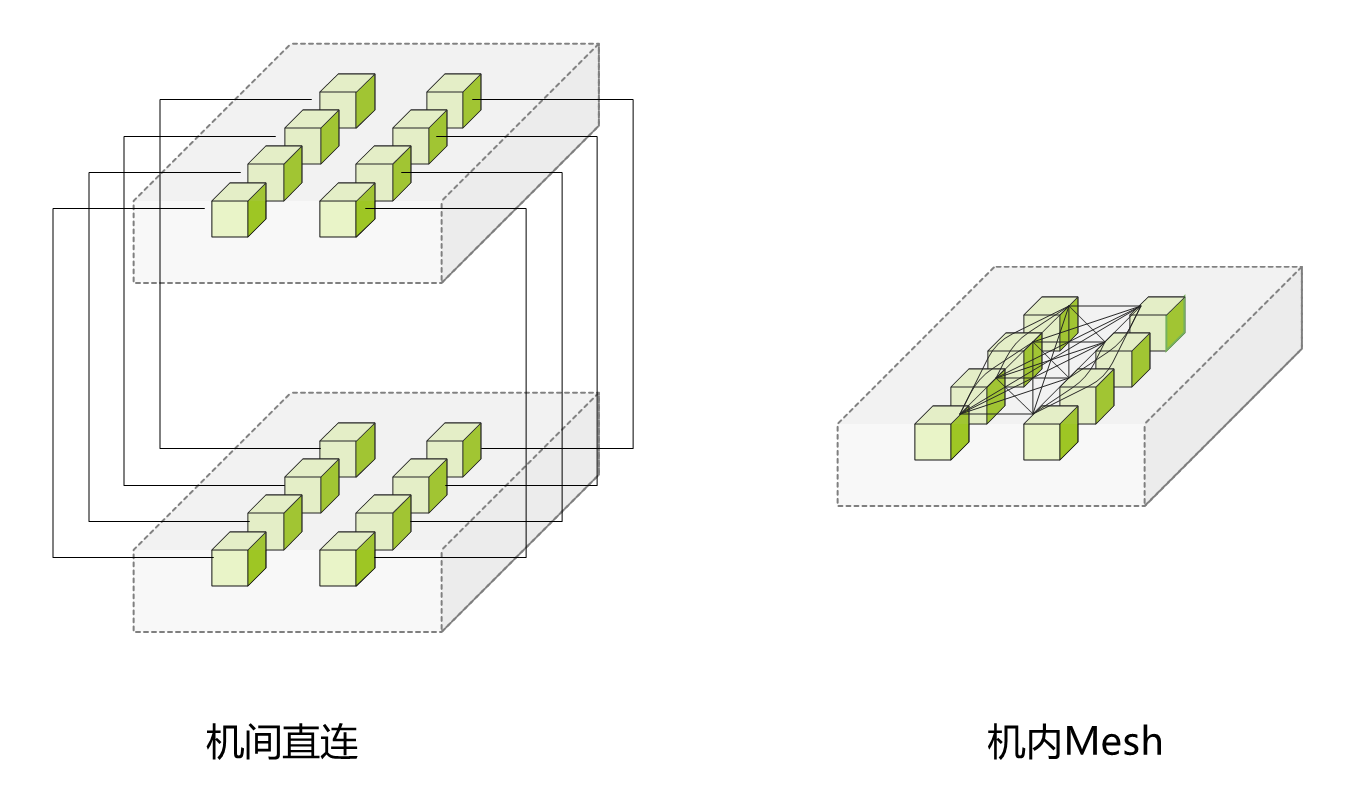
▲全互连拓扑
交换树型(Tree+)拓扑。这是迈向超节点的关键一步。单层Tree+结构通过1层交换机将64张GPU卡整合为统一计算单元,实现4000GB/s总带宽和点对点全互联。为进一步扩展,双层Clos拓扑分为框级(L1)和系统级(L2)互联,可支持1024张GPU的大规模集群。
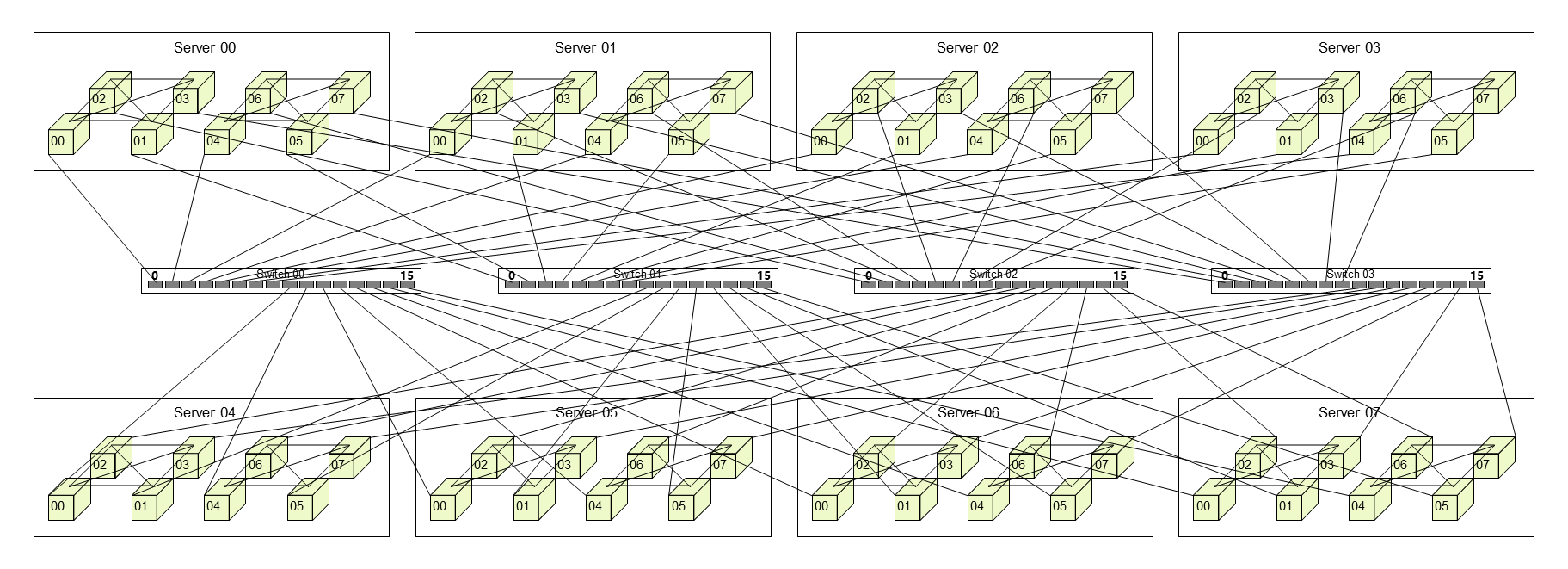
![]()
▲单层Tree+拓扑
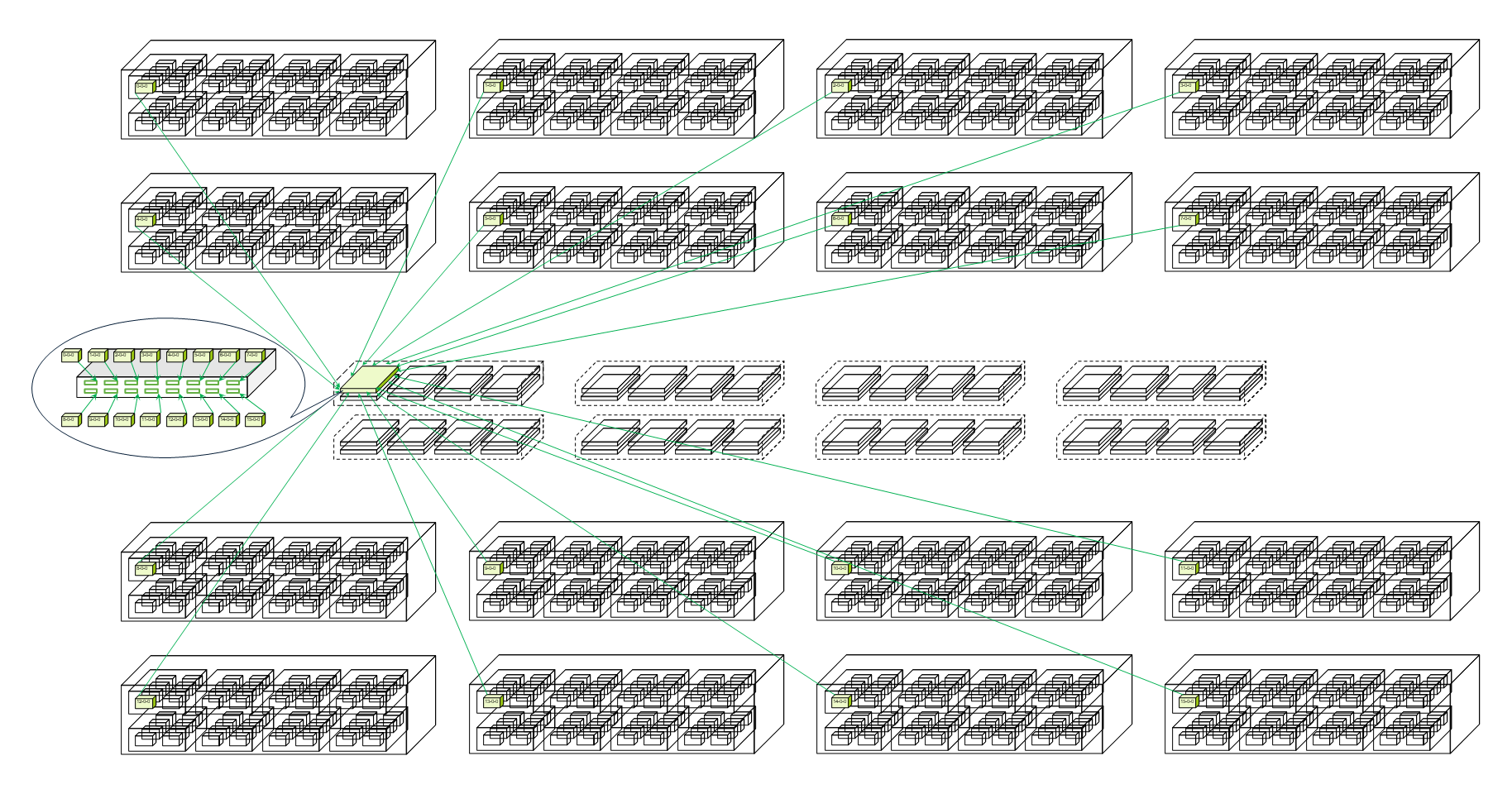
▲双层Clos拓扑
Dragonfly类拓扑。专为大规模并行计算设计,Dragonfly拓扑在保持较低硬件成本的同时实现局部高带宽、全局低延迟。其核心特点是"组内高速互联+组间有限全局链路"的层次化设计,广泛应用于HPC和超大规模数据中心。
▲Dragonfly类拓扑
Torus拓扑。通过二维或三维环形结构连接节点,Torus拓扑支持数千甚至上万颗芯片的互联。其最大优势在于故障域隔离——单个节点故障不会影响全局,同时将故障范围限制在局部单元内,显著提升系统可靠性。
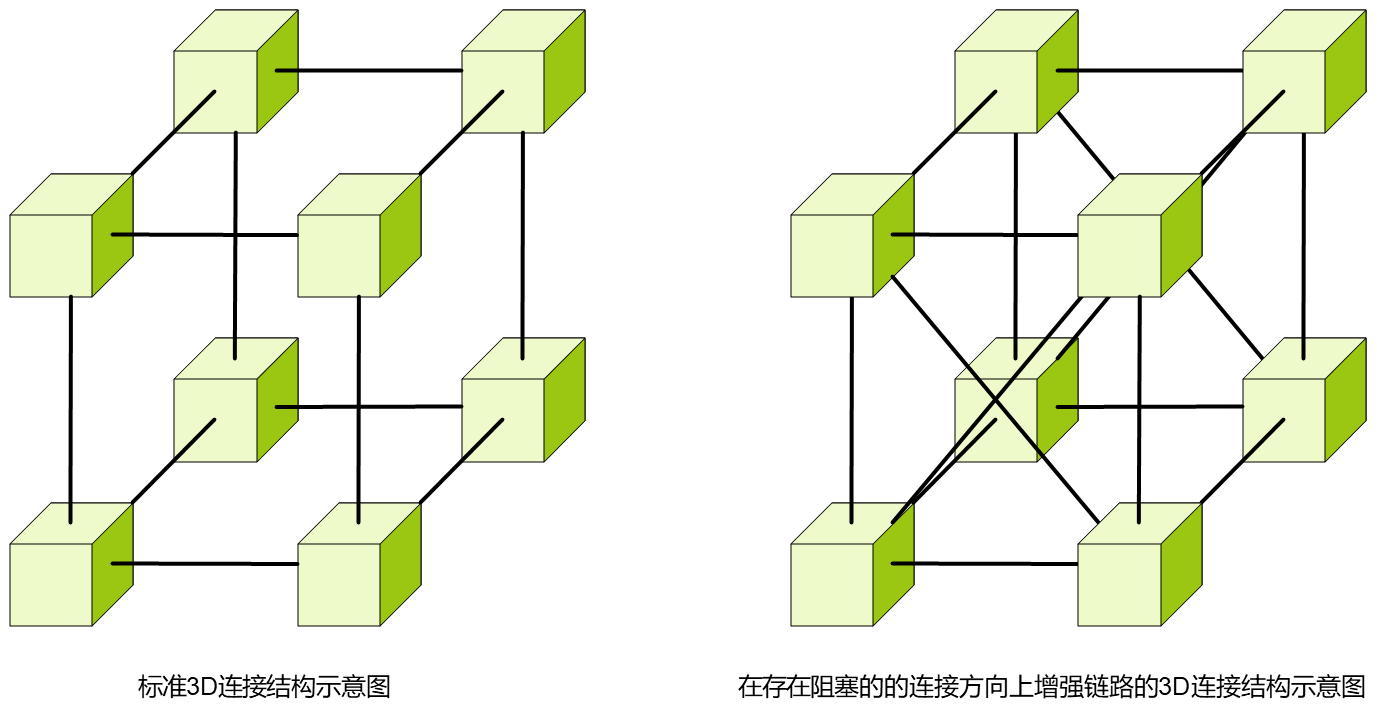
▲Torus拓扑
| 未来演进分析
超节点网络正朝着三个维度持续进化:
• 更高灵活度:拓扑结构将更加多样化,AI训练倾向全互连或胖树结构,科学计算可能偏好Torus结构,而光互联技术可以更好地适应灵活多变的需求。
• 更高速率:互联协议持续升级,链路速率将进入TB/s级别,通信延迟进一步优化以匹配计算单元效率,光互联技术在传输速率上限方面具备显著的原生优势与极大拓展潜力,可满足日益增长的通信需求。
• 更高带宽密度:在AI算力爆发、智能化加速的背景下,数据传输需求将达到PB级甚至更高,面临在有限空间实现巨大互联带宽的矛盾,转向光互联以提升单位面积传输能力将成为必然选择。
从硬件层面的简单互联,到系统级的硬网软协同设计,超节点网络架构的演进是对AI算力需求持续增长的精准回应,为大模型等前沿AI应用筑牢基础。
光子算数的光直连GPU超节点系统,通过光互联网络拓扑优化,将众多直接出光的GPU进行光互联,从而整合为“一张巨型的GPU卡”,实现了算力资源的高效协同。这种聚合并非简单的硬件堆叠,而是基于先进的网络拓扑设计,突破了传统集群的通信瓶颈,体现了系统级创新的优势。
未来,随着技术持续迭代,基于光互联技术的超节点有望成为AI基础设施的“标准配置”,推动智能世界加速到来。

