
 2026年01月27日
2026年01月27日在大模型训练需求爆炸式增长的今天,算力集群规模已从万卡向十万卡甚至百万卡级别迈进,理论算力规模持续飙升。然而,越来越多的实践表明:单纯增加GPU数量并不能实现算力投入与训练效率的线性提升。真正的瓶颈,隐藏在GPU之间的“对话效率”——即互联技术之中。
| 算力集群的效能瓶颈:低效互联吞噬计算能力
传统电互联在短距离、低带宽场景下尚可应对,但在超大规模算力集群中,带宽、延时、信号衰减已触及物理极限。随着传输频率提升,趋肤效应和导体损耗加剧,导致其速率难以突破,传输延迟高达数百微秒。数据显示,在大模型训练过程中,超过30%–40%的时间消耗在GPU等待数据同步上。这意味着,即便拥有海量GPU,若互联不畅,系统整体效率仍将严重受限。
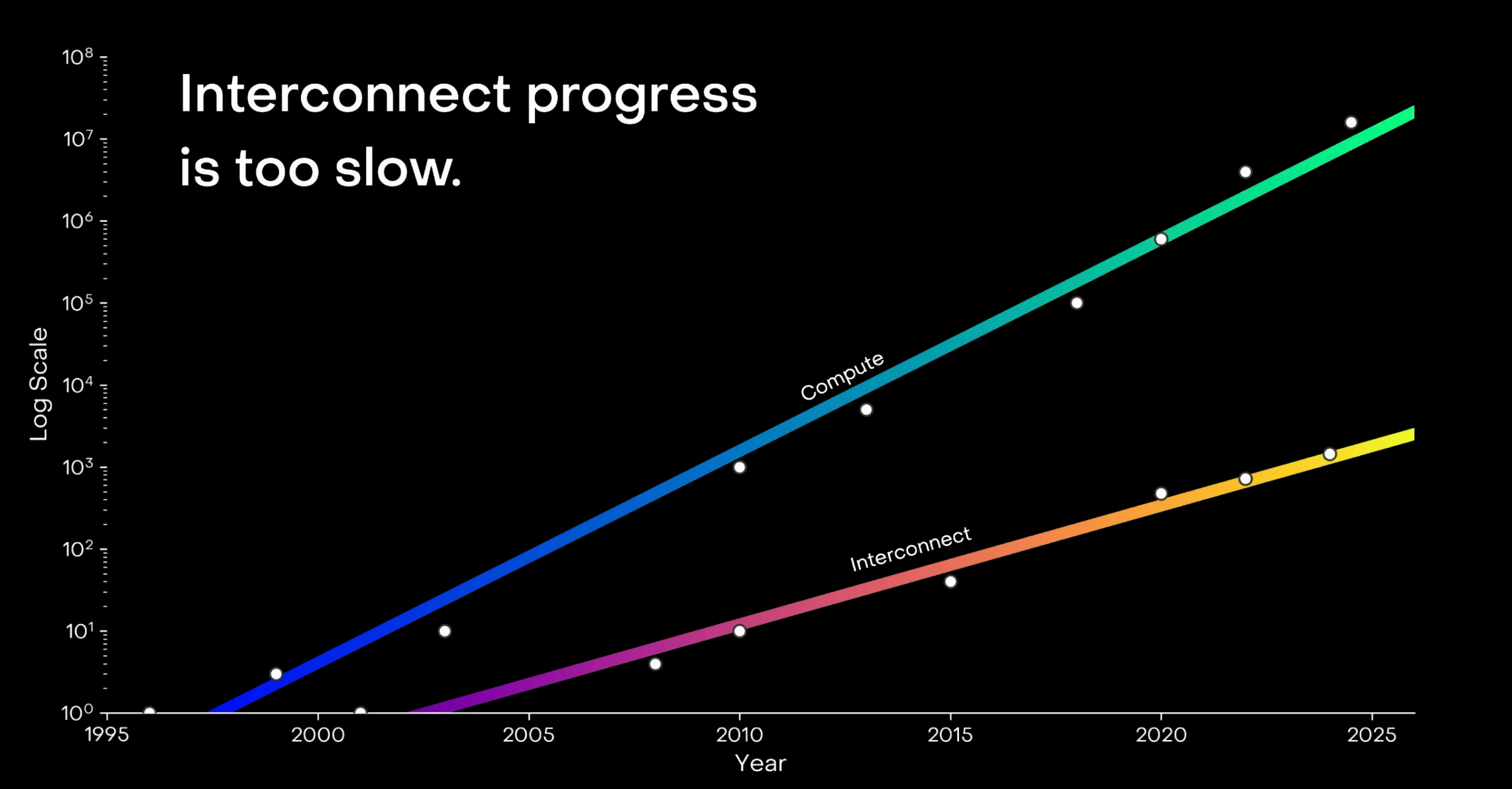
▲网络传输能力与算力需求不匹配,资料来源:Lightmatter
| 光互联的破局之道:以光传输重构性能边界
相较于电互联,光互联优势根植于底层传输原理,在延迟、带宽、功耗等关键指标上实现代际跨越。
降低延迟:光在光纤中的传播速度约20万公里/秒,接近真空中光速的2/3,远高于信号在铜缆中的传播速度。此外,光电集成技术将光引擎与GPU芯片集成在同一基板上,电链路长度缩短至厘米至毫米级,路径缩短直接带来40%以上的延迟降低。

▲光互联连接示意图,资料来源:ASE
提升带宽:光波频率高达百THz量级,频谱资源远超电信号(通常<100GHz)。借助波分复用技术,单根光纤可同时传输多个波长的光信号,实现带宽的成倍扩展。
抗干扰与低功耗:光子传输不受电磁干扰影响,且光纤损耗极低,能够有效避免电阻热损耗,显著降低整体功耗。
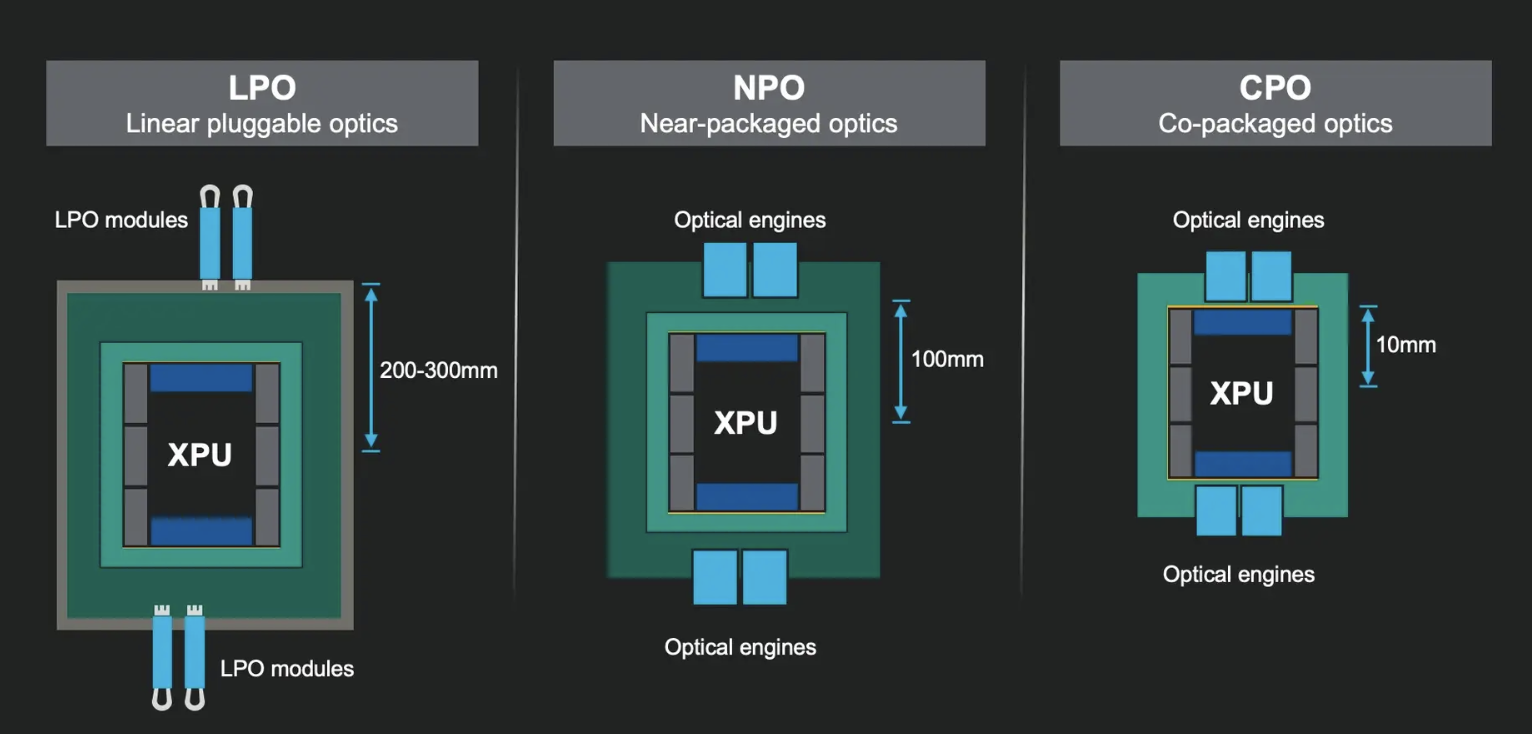
▲光互联技术演进(从LPO到CPO),资料来源:Marvell
| 光互联技术应用:光直连GPU超节点系统
超节点通过高速光互联将数百至上千颗GPU整合为单一逻辑单元,是实现算力密度飞跃的关键架构。其对互联网络提出极致要求:微秒级时延、TB/s级无阻塞带宽。光互联技术通过光芯片与GPU芯片的集成、网络拓扑优化等手段,为超节点提供底层支撑,但其在算力建设和生态兼容性方面仍需系统级优化。
在光互联技术落地方面,以光子算数为代表的国内企业通过自研光互联与硅光集成技术,推出光直连GPU超节点系统,在大模型推理和训练应用中,该系统显著降低通信延迟与功耗,极大提升了训练效率,推动光互联从“可选项”发展为算力集群的“生存刚需”。
算力竞争的下半场,不仅是芯片的比拼,更是互联能力的较量。光互联技术以其固有优势,推动算力架构向更加高效、稳定、绿色的方向演进。

