
 2026年01月16日
2026年01月16日| 高速互联技术:直击 AI 时代大算力、高带宽、低能耗需求
当前,AI大模型仍处于持续迭代过程中,其参数规模和数据处理量呈现指数级增长态势,催生出对大算力、高带宽、低能耗的现实需求。
在算力层面,可以预见AI发展仍将由算力扩张主导。根据Epoch AI对知名AI模型训练计算量的预测,自2010年以来,知名AI模型的训练计算量每年增长约4-5倍,如果这种趋势持续,到2030年最大的模型将使用10e^29 FLOP进行训练。
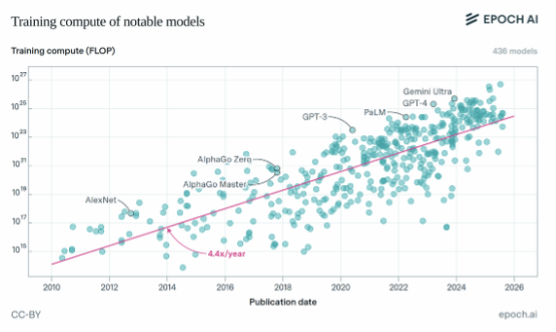
▲资料来源:Epoch AI
在带宽层面,表现为大模型(LLMs)的互联带宽需求,远超内存带宽的增长速度,二者之间存在着巨大的差距。大语言模型参数规模,从数亿增长到万亿,甚至未来将增长到数万亿,对内存带宽的需求也呈指数级上升。然而,内存带宽却是线性增长,相对滞后,无法为大语言模型提供足够支持。
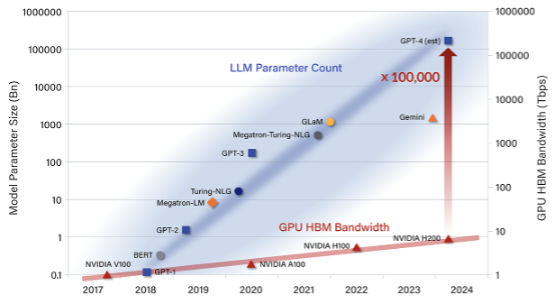
▲资料来源:Avicena
在能耗层面,AI大模型的大规模应用也将带来前所未有的能源消耗。根据Avicena预测数据,信息和通信技术(ICT)领域的总电力需求将会加速增长,预计到2030年将在全球电力需求中占据20%以上的份额,其中数据中心将占据更大的份额。
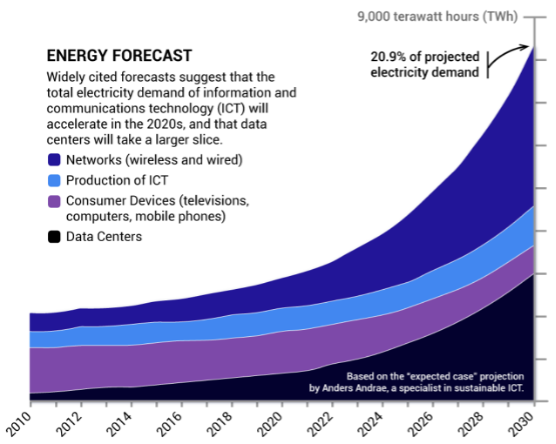
▲资料来源:Avicena
在此背景下,高速互联技术逐步成为实现AI智算中心处理器、交换机、内存之间高密度、高带宽、低功耗连接的重要手段。依托高速互联技术可以实现:打破“算力孤岛”,释放集群协同能力;突破“内存墙”,实现数据高速流转;实现“按需传输”,避免“满负荷运行”的无效能耗。
| 超节点浪潮下电互联性能瓶颈显现,光互联性价比攀升
在AI大模型应用的拉动下,单节点超过8卡的大带宽、低时延集成计算单元“超节点”迎来发展浪潮。不同于传统节点架构“向外扩”(Scale Out)的模式,超节点架构通过构建Scale Up高速互联体系实现规模破局,并且通过叠加Scale Out组网构建集群化组网架构。随着超节点概念日趋成熟,其内涵也从最初聚焦于硬件互联,深化为软硬件一体化的全栈协同设计。
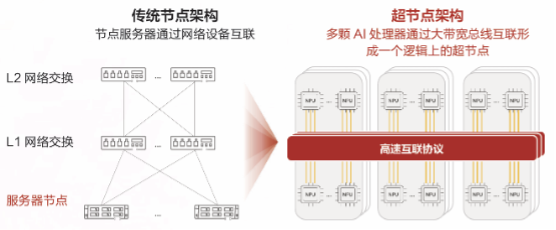
▲资料来源:《超节点发展报告2025》
互联技术是构建超节点架构的底层支撑和关键要素,伴随大模型技术快速发展,传统电互联在传输速率、能耗、距离等方面的瓶颈日益凸显。从物理层面看,铜导线与电子传输性能已逼近天花板,即“互联墙”(interconnect wall)。GlobalFoundries合作伙伴IMEC的研究数据显示,电互联(铜缆、PCB铜线等)在带宽、功耗、传输距离的综合指标上已较难实现突破。
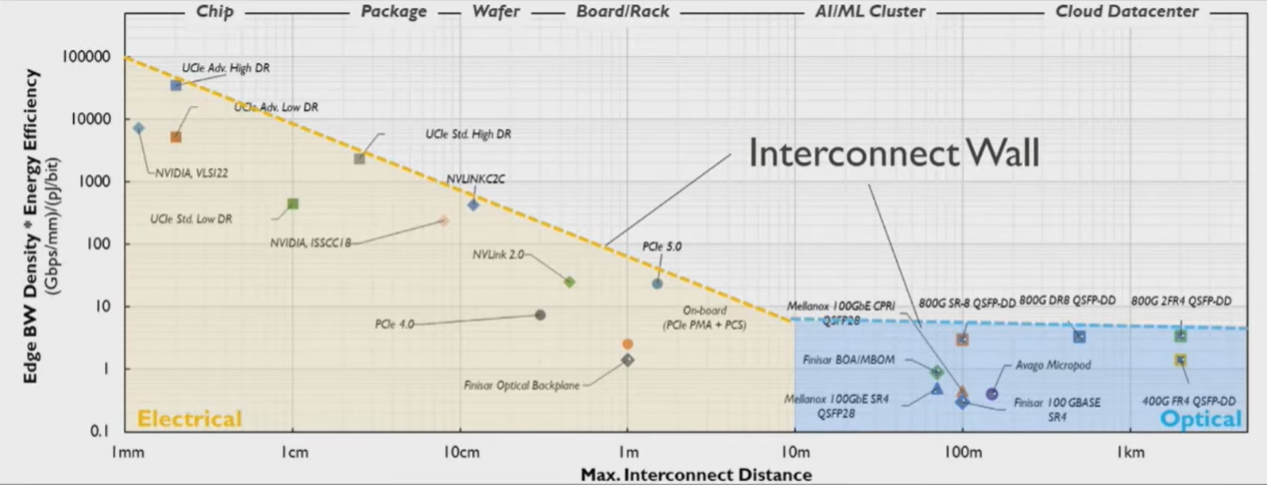
▲资料来源:IMEC,GlobalFoundries
光互联天然具备打破“互联墙”的能力,随着市场需求向更高性能要求演进,光互联有望成为替代铜互联的新一代信号载体。光互联以“光子”为信息载体(通过光纤、硅光芯片传输),具备高频、低损耗、无电磁干扰等优势,能够突破“速率墙”、“距离墙”和“能耗墙”的限制,或将成为突破万卡向十万卡智算集群“带宽、延迟、功耗”三重瓶颈的关键技术。
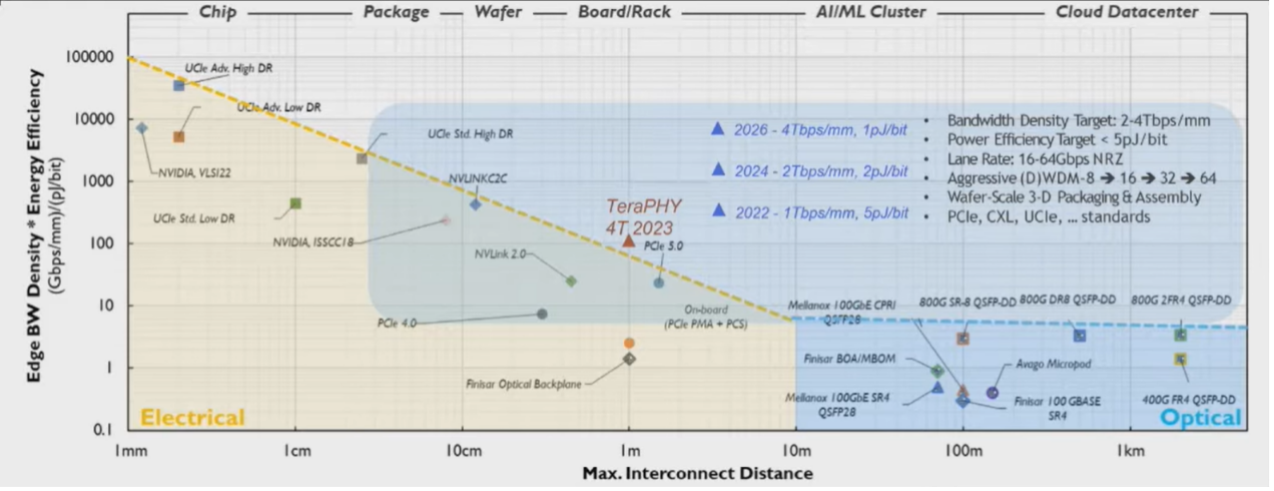
▲资料来源:IMEC,GlobalFoundries
| 光互联超节点:蓝海赛道的机遇与突破
当前,全球头部科技大厂与前沿创业公司均在加速布局该领域。海外阵营中,Ayar Labs、Lightmatter、Intel、Celestial AI 等企业是核心参与者。近期,Marvell 宣布拟以最高55亿美元收购Celestial AI,后者在多机柜超节点光互联领域的技术布局极具代表性,这一收购事件也迅速引爆了市场。国内赛道同样热度渐起,光子算数、曦智科技、光联芯科等企业已入局,积极开展相关技术攻关与产品研发,部分企业已实现量产交付。

▲Celestial AI的Photonic Fabric大幅提升Scale-up互联效率
整体而言,光互联超节点市场仍处于发展初期,是一片亟待开拓的蓝海。未来,节点内光互联技术的商业化突破,需聚焦两大核心方向:一是放大速度优势长板,进一步拉开与传统铜连接的性能差距,满足节点内更高传输速率的应用需求;二是借助新材料、先进封装等技术手段,针对性优化时延、功耗与成本三大关键指标,推动技术更快走向规模化落地。

